
Touch interaction has become practically ubiquitous in developed markets, and that has changed users’ expectations and the way UX practitioners think about human–computer interaction (HCI). Now, touch-free gestures and Natural Language Interaction (NLI) are bleeding into the computing mainstream the way touch did years ago. These will again disrupt UX, from the heuristics that guide us, to our design patterns and deliverables.
HCI Is Getting “All Shook Up”
With touch, people were given a more natural, intuitive way to interact with computing devices. As it moved into the mainstream, it opened up new interaction paradigms. Touch-free gestures and NLI, while not exactly new, are just now moving into the computing mainstream thanks to Microsoft and Apple, respectively. If they catch on, these interaction models may open up further paths toward a true Natural User Interface (NUI).
Touch-free gestures
Microsoft’s Kinect popularized this interaction model for the Xbox gaming platform. Following that, they have made the Kinect available for Windows, and smart TVs like Samsung’s are moving touch-free gestures out of gaming and into our everyday lives.
Kinect for Windows has an interesting feature called near mode, which lets people sitting in front of a PC use the touch-free gestures without standing up. A benefit for productivity software is the reduced need for interface elements: on-screen artifacts can be manipulated more like physical objects. Another benefit is the ability to use computers in situations when touching them is impractical, like in the kitchen or an operating room.
Natural-Language Interaction
The idea of talking to our computers is not new, but only with the success of the iPhone’s Siri is it coming into the commercial mainstream. The best part of NLI is that it mimics the ordinary way humans interact with each other, which we learn very early on in life.
Not only does NLI (when done well) make the interaction with a computer feel very natural, it also primes people to anthropomorphize the computer, giving it a role as a social actor. Giving voice to a social actor in people’s lives bestows immense power upon designers and content creators to build deeply emotional connections with those people.
Fundamentals of Interaction
While new technologies offer greater opportunities for richness in interaction, any such interaction occurs within the context and constraints of human capability. As we move forward to welcome new interaction models, we are building a knowledge infrastructure to guide UX practitioners in taking advantage of them. HCI fundamentals serve as our theoretical basis.
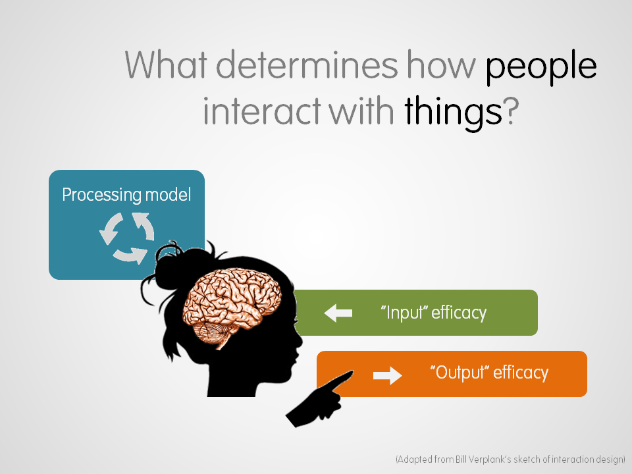
Bill Verplank’s model of human–computer interaction describes user interactions with any system as a function of three human factors:
- Input efficacy: how and how well we sense what a system communicates to us
- Processing model: how and how well we understand and think about that communication
- Output efficacy: how and how well we communicate back to the system
By using design to support these elements of the user experience, we can enrich that experience as a whole. These human factors serve as a useful thought framework for envisioning and evaluating new design heuristics and patterns.
Heuristics
While the heuristics we know and love still apply, some additional ones will help us make better use of touch-free gestures and NLI. Here are some examples:
- Gestures must be coarse-grained and forgiving (output efficacy) – People’s hand gestures are not precise, even on a screen’s surface. In mid-air, precision is even worse. Expecting too much precision leads to mistakes, so allow a wide margin and low cost for errors.
- A system’s personality should be appropriate to its function(processing efficacy) – When speaking with something, people automatically attribute a personality to it. If it speaks back, its personality becomes better defined in users’ minds. Making a productivity program (e.g., Excel or Numbers) speak in a friendly and understanding way could make users hate it a little less. Making an in-car navigation system firm and authoritative could make it feel more trustworthy. Siri makes mundane tasks such as planning appointments fun because Apple gave her a sense of humor.
- Users should not be required to perform gestures repeatedly, or for long periods of time, unless that is the goal (output efficacy – Repetitive or prolonged gestures tire people out, and as muscle strain increases precision decreases, affecting performance. If the idea is to make users exercise or practice movement though, this doesn’t apply.
- Gestural and speech commands need to be socially appropriate for user’s environmental contexts (input and output efficacy) – The world can see and hear a user’s gestures and speech commands, and users will not adopt a system that makes them look stupid in public. For example, an app for use in an office should not require users to make large, foolish-looking gestures or shout strange verbal commands. On the flipside, including silly gestures and speech into a children’s game could make it more interesting.
- Affordances must be clear and interactions consistent (processing efficacy) – As Josh Clark and Dan Saffer remind us, interface gestures are more powerful but less discoverable than clickable/tappable UI elements. The same goes for speech. Gestures and speech in an interface each adds an additional interaction layer, so clear affordances and consistent interaction are critical for those layers to work.
Patterns
Since touch interfaces became mainstream, gesture libraries like this one have appeared to help designers communicate touch interactions. Not limited to the X and Y axes on a screen, touch-free gestures allow designers to leverage depth and body movements. Combined with natural speech interaction, designers can create rich multi-modal interactions, where, for example, a user’s hands control one aspect of the system while her voice controls another.
“Near Mode” Gestures (Explicit Input)
The original Kinect uses full-body gestures, but near mode is what makes the new version so special. Here are some “sitting in front of your PC” gestures, with illustrations based on this gesture library by think moto.
- Swipe, Spread, and Squeeze: These are the most basic gestures and represent full-hand, touch-free translations of finger-sized touch gestures.
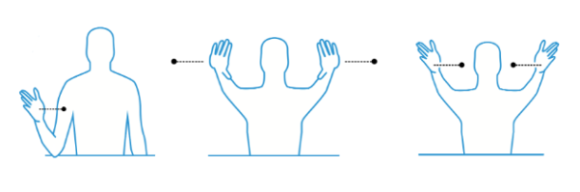
- Push and Pull: Users could use these gestures to move on-screen artifacts closer or farther away.
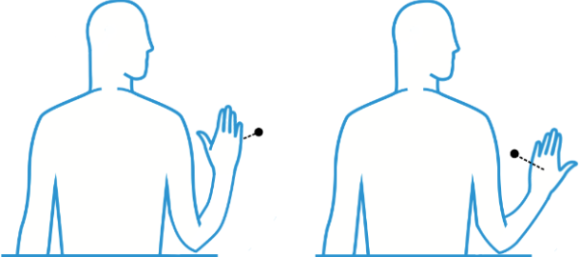
- Grasp and Release: Hand-level Spread and Squeeze gestures can be used for interface-level zooming actions, so finger-level pinching can be used to grasp on-screen artifacts. When a user “takes hold” of such an artifact, she can manipulate it using dependent gestures.
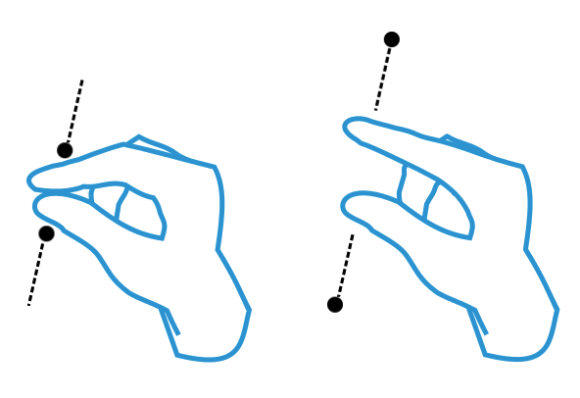
- Twist: One such dependent gesture is Twist. Now that artifacts can be manipulated in a third dimension, a “grasped” artifact can be twisted to change its shape or activate its different states (e.g., flipping a card or rotating a cube).
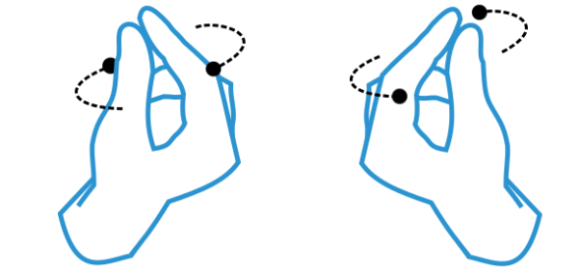
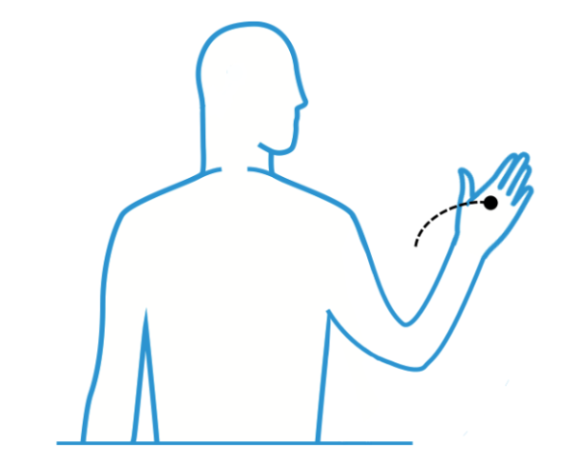
- Throw: Besides twisting an on-screen artifact, a user can throw it to move it a long distance quickly. This could trigger a delete action or help users move artifacts in 3D space.
Body Sensing (Implicit Input)
In addition to new opportunities for gestural input, a Kinect sensor on PCs could detect other aspects of our body movements that might indicate things like fatigue or emotional state. For example, if gestural magnitude increases (e.g., if a user’s gestures become bigger and wilder over time), the system could know that the user might be excited and respond accordingly. With productivity software, such excitement might indicate frustration, and the system could attempt to relax the user.
Another implicit indicator is gestural accuracy. If the system notices that a user’s gestures are becoming lazier or less accurate, the system might recognize that the user is tired and encourage him to take a break. And although it’s not a strictly implicit indicator, sensing whether a user is seated or standing could enable different functions or gestures.
Speech Interaction
The complexity of human languages makes it less straightforward to create discrete patterns for NLI than it is for gestures. However, there are structures inherent in language that could provide a basis for such patterns.
For example, there are two major types of user input: questions (to which a system returns an answer) and commands (which cause a system to perform an action). Looking deeper, individual sentences can be broken down into phrases, each representing a different semantic component. Books such as Speech Technology, edited by by Fang Chen and Kristiina Jokinen, show how the fields of linguistics and communication provide valuable insight to designers of natural-language interfaces.
Deliverables
Perhaps the biggest challenge with using novel interaction models is communicating with stakeholders who are not yet familiar with those models. Visualizing things that don’t exist is difficult, so UX designers will have to find new ways to communicate these new interactions.
Specifications

Interaction design specs are still two-dimensional, because that’s all they need to be. For some touch-free gestures though, variables such as “distance from the screen” or “movement along the z-axis” will be important, and those are best visualized in a more three-dimensional way.
Speech interactions are even more complex. Since a user’s interaction with the system literally becomes a conversation, the design needs to account for extra contingencies, e.g., users expressing the same command with different words, accents, or intonations. A natural language interface must accommodate as many of these variations as possible.
Also, there are more variables that play a role in the way a system communicates to users. Its tone, choice of words, cadence, timbre, and many other factors contribute to how a user perceives that system.
Personas
Because speech-enabled computers will become social actors in people’s lives, their (perceived) personalities are of critical importance. Thankfully, we can apply existing skills to doing that.
UX professionals have traditionally used personas to illustrate types of users. With computers communicating like humans, the same technique could be used to illustrate the types of people we want those computers emulate. System personas could be used to guide copywriters who write speech scripts, developers who code the text-to-speech engine, or voice actors who record vocal responses.
For a system to show empathy, it could measure changes in users’ speech patterns, again recognizing excitement, stress, or anxiety. If a user is getting frustrated, the system could switch from an authoritative persona (showing reliability) to a more nurturing one (calming the user down).
Prototyping
Responding elegantly to users’ body movements and speech patterns requires a nuanced approach and clear communication between stakeholders. Along with specifications, prototypes become more important because showing is more effective than telling. This holds true for both testing and development.
For now, there is no software package that can quickly prototype Kinect’s touch-free gestures; downloading the SDK and building apps would be the only way. For speech though, there are a few freely available tools, such as the CSLU toolkit, which allow designers to quickly put together a speech interface for prototyping and experimentation.
Until prototyping tools get sophisticated enough to be fast, flexible, and effective, it looks like we’re going to have to get back to basics. Paper, props, storyboards, and the Wizard of Oz will serve until then.
The Big Wheel Keeps on Turning
User interfaces for computers have come a long way from vacuum tubes and punch cards, and each advancement brings new possibilities and challenges. Touch-free gestures and natural language interaction are making people’s relationship with computers richer and more human. If UX practitioners want to take full advantage of this changing relationship, our theories and practices must become richer and more human as well.
Let us move forward together into this new interaction paradigm and get closer to our users than ever.


