The world is built on the idea that numbers can’t be wrong; that data is objective and only works if it’s good enough to be there. Furthermore, systems do not have their own virtuous minds. Instead, they invent an explanation depending on the information provided to them. Instead, they make up a reason based on the data that they are given. We tend to forget that these codes are based on one’s own biases, experiences, and attitudes. As Caroline Perez, a feminist and author of Invisible Women says, “that because of the way machine-learning works, when you feed it biased data, it gets better and better — at being biased.”
Therefore, past data is sexist or invisible because gender and caste-based minorities have been excluded from the equation. As AI gets better, it reduces human dignity to a data point that doesn’t care about the problems we’re trying to solve with AI in the first place.
Data scientists have said that there are two main ways that AI perpetuates gender bias. One is caused by Algorithmic and design flaws that make decisions that aren’t fair to people who are of a certain gender, ethnicity, religion, geographic location, or other type of group. This can be seen as gender in technology from a feminist point of view. The other is the reinforcement of gender stereotypes through new digital products that project a technological gender.
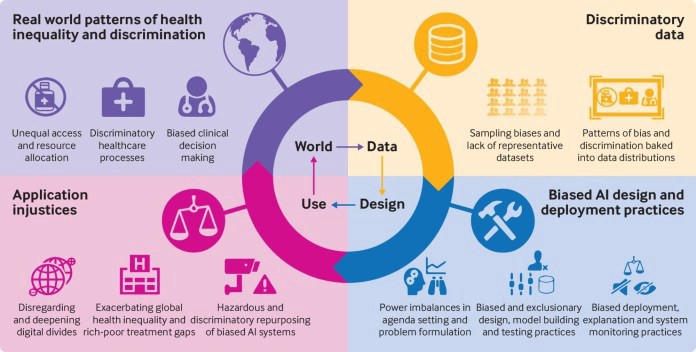
There are a lot of reasons why datasets are skewed.
An algorithmic bias that goes unnoticed and has a huge impact and can be life-changing. There have been a lot of theories about why AI systems are making people think that women are less intelligent than men. In AI, this is called Implicit bias. It makes the whole decision-making process unfair at the very start when the coder or the designer makes machine learning models based on their own stereotypes.
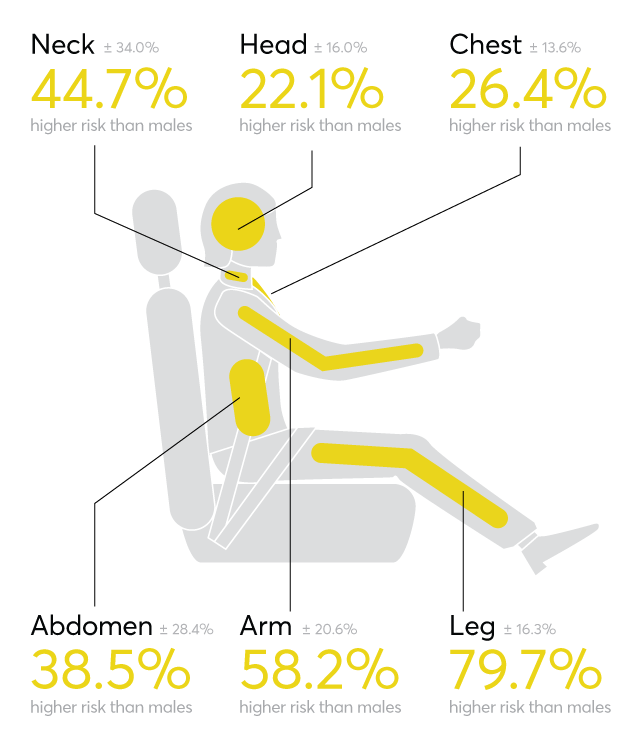
There are other stages of sampling and analysis that are affected by this fact, as well. For example, a woman is 47% more likely to be seriously hurt and 17% more likely to die in a car accident than a man. Because most car seats are made for taller and heavier men, and until recently, only male dummies were used for crash tests. Women, even teenagers, the disabled, obese, and the elderly, aren’t taken into account when the car is made by men for men’s bodies.
Female Increased Risk of Injury
Another common explanation is Coverage Bias in training datasets. It’s usually not complete, or it doesn’t show the population at large in the same way that it should. That’s why algorithms often make mistakes.
A 2015 drug study to see how alcohol affects Flibanserin, also known as “Female Viagra,” had 23 male participants and only two female participants. Premenopausal women were supposed to take the drug to boost their libido. Addyi is a brand name for a drug that the FDA approved that same year. It is now sold under that name.
The AI systems, as a result, are likely to show the digital divide between different groups of people, too. Most of the time, the historical data used to train the algorithm isn’t inclusive of how people used to do things in the past, which could make historically disadvantaged groups less likely to get jobs or other opportunities. It was reported in 2018 that Amazon’s hiring practices were skewed toward women because the past 10 years of hiring data was mostly male in technical jobs. This is a well-known example of this bias. Research shows that candidates who used terms like “women’s chess team” and “women’s college,” no matter how well qualified they were, were down-ranked by the algorithm. When the algorithm was made public, the company had to break up the group that made it.
Also, Confirmation Bias can make algorithms hard to work with. This is when a researcher only looks at or interprets data that agrees with his own ideas, preventing him from looking at other possibilities and questions. The data wasn’t collected from everyone in the target group in a random way, which would have led to the most generalizable results. Participation bias happens when the group isn’t taken into account when it comes to the different participation and drop-out rates of different population groups. In addition to the flaws in the data that were mentioned above, there may be another kind of discrimination in Big Data that people don’t pay attention to: “Outliers.” In decision-making situations, the outliers can be a minority or a group that isn’t well-represented.
The widespread use of AI systems makes it important to point out that a discriminatory algorithm that doesn’t like people because of their age, race, pin code or other factors is hurting their human right to equality and could end up repeating the mistakes of the past. A toxic tech environment assumes that its users are monoracial, able-bodied, and heteronormative, which is not true. This is because, as we learn more about the many different types of gender and sexuality, these groups that aren’t as well-known are more likely to be labeled as atypical by the system itself.
Triangulation of Ideas
Artificial Intelligence is ready to have the biggest impact on the Healthcare, Automotive, and Financial sectors by 2030, which means that these industries have the most room for improvement and positive change. With more personalized solutions, the creators will also get a lot of slower competitors out of the market. This is because they will be better at listening to what people want. Big Data is still very important for the future of the relationship between humans and machines.
The management of such a hegemonizing industry will be the future’s headache. It raises concerns about digital human rights, privacy, and the right to non-discrimination, all of which this sector is expected to unmanageably raise in the near future. Unless it is dealt with in a unique way, the progress made by several waves of the Feminist movements, Civil Rights movement, minority rights, and LGBTQ+ rights movements around the world could be at risk in the near future.
To make sure that the AI doesn’t have a bias, there will need to be three different ways for people to do it. A simple way to solve the problem is to keep gender-specific data. Culture: People don’t think about the need for women’s data because “human” almost always refers to a man, so they don’t think about it. The “male default” problem is to blame for a lot of the near-death risks that women face every day. At the very beginning of the game, we need to make sure that our data is both intersectional and disaggregated. This means that we need to look for gender and racial diversity in our creators.
A big part of understanding AI and its effects is being able to understand how the AI system works, which makes decisions based on data. Artificial neural networks and deep learning tools are being used by businesses to solve the Black Box AI problem. This is when even the programmer can’t figure out how the machine caused a certain result. It’s not noticeable until something wrong or unusual is found.
Artificial neural networks are said to be similar to human neural networks in the brain. Judgments are said to be made by recognizing patterns and examples from the past, which is still not clear. In the face of uncertainty and ethical issues, simpler, more interpretable types of artificial intelligence should be favoured. It may not be as good as more advanced AI models, but this can be explained because it is ethical.
Tricia Wang, a tech ethnographer, came up with another way to solve the problem. She said that thick data should be used with big data. With the growth of Big Data, which Wang calls “Quantification Bias”. This is the natural tendency to value things that can be seen and measured over things that can’t be seen or measured. Data restricts our view of the world by taking a very one-sided, positivist approach. She has demonstrated that combining the finest of human intelligence with qualitative and behavioral insights is critical to achieving a more complete picture.
Cathy O’neil further articulated in her popular TED Talk that, “You need two things to design an algorithm — past data and a definition of success”. According to her, a regular check on both the integrity of the data that came before and the definition of success to make sure it’s fair can significantly cut down on the spread of existing bias. This brings into enquiry who is answering the questions? What questions are they asking? Who is designing these new systems? The person who decides what data is used to train the products — a re they following the rules for AI ethics and gender equality? Do they give a damn?
See Cathy’s TED Talk here: https://www.youtube.com/watch?v=_2u_eHHzRto
Rather than putting our world at risk, automated systems need to be made and trained to respect and recognize the diversity of our world. Globally, STEM and digital skills education ecosystems are dominated by men, which leads to a severe lack of minority groups in technology products. What comes out even more clearly through this gender-based inquiry process is that a feminist point of view is very important for making sure everyone is treated equally. Patriarchal systems that have been around for hundreds of years can’t be allowed to show up in latent forms through technology that was made by men. There is an urgent need for more women to be at the table when it comes to making and managing futuristic, data-driven innovations. This means that the representation isn’t just a matter of technology or morality, but also a personal and political one.