Overview
There are many clever ways to incorporate generative AI and LLMs into your machine-learning pipelines. I’ve discussed a number of them in my previous posts here and here. One thing I haven’t mentioned yet, however, is all the potential ways leveraging these techniques can go sideways.
Yes, unfortunately, GPT isn’t all kittens, unicorns, and roses. Despite all the promise these models have to offer, data scientists can still very much get themselves into trouble if they aren’t careful. It’s important to consider the downside and risks associated with trying to take advantage of these approaches, especially since most of the risks aren’t immediately obvious.
In this article, I’m going to cover four major risks that everyone should be aware of when incorporating generative AI into their ML modeling:
- Randomness
- Target leakage
- Hallucination
- Topic Drift
Randomness
Today’s generative models, such as OpenAI’s chatGPT-4, are non-deterministic. That means you can supply the exact same prompt twice and get back two entirely different responses.
Don’t believe me, let’s try it out:
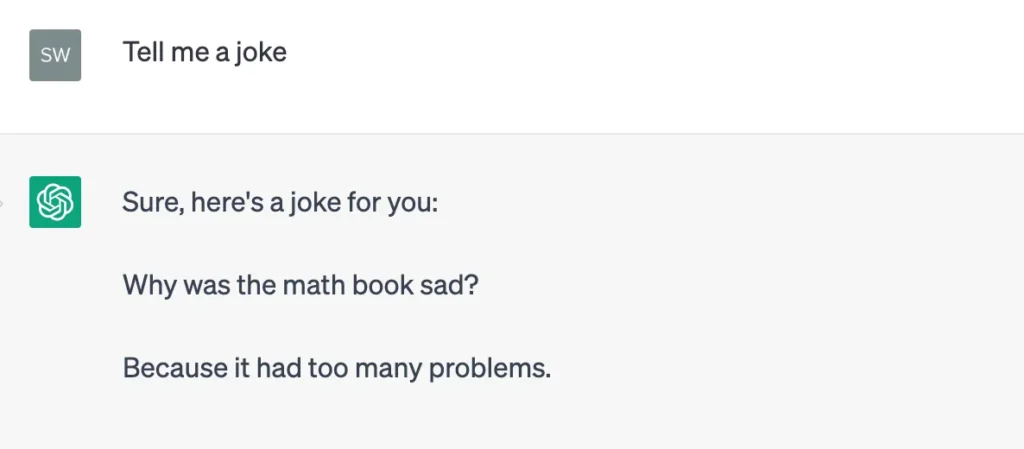
Joke #1
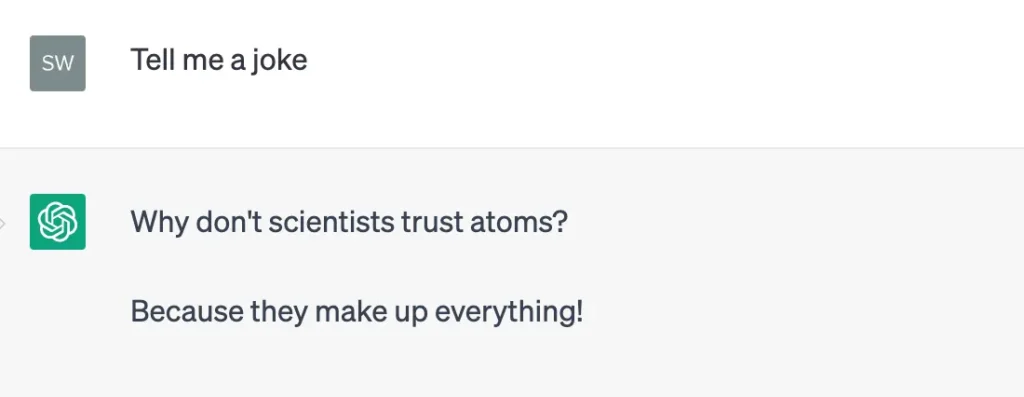
Joke #2
These responses are disappointing for two reasons: one, I expected better jokes, and two, we got back two different jokes even though we supplied the exact same prompt.
I can probably come to terms with the bad jokes, but the randomness is a problem. Non-determinism is problematic for a number of reasons.
First, it’s hard to get a clear estimate of how well your models will generalize out into the future since the responses GPT returned when you first trained your model may change unexpectedly in ways you can’t predict when you re-generate them moving forward.
Second, reproducibility becomes challenging. In general, data science should be treated like modern software development — and that means reproducibility is a requirement! Sure, you can always store a copy of your training data with the generated responses, but you’ll never be able to replicate your modeling pipeline from scratch since you can’t guarantee the same responses. That’s no bueno.
Luckily, there’s a potential solution for both of these problems. Rather than just making a single call to GPT for each observation (such as extracting entities), make the same call 10 times and return the most common response. I chose 10 because I found it worked well, but you can test whichever number you like — there is nothing scientific about my choice. Keep in mind that this is still an active area of research and we very well may get something akin to setting a random seed in the near future.
Target Leakage
The second risk I want to call out is slightly more nuanced. Before we delve into how leveraging GPT can cause leakage, I first want to explain the concept of target leakage more generally (if you’re already familiar with this concept, go ahead and skip the next few paragraphs).
Target leakage is a common issue that creeps up when information about the target variable (i.e., the outcome or label that the model is trying to predict) inadvertently influences the input features used for training the model. This can lead to an overly optimistic assessment of model performance during training and validation, but poor performance in real-world situations when the model is applied to new, unseen data.
Leakage typically happens when the model is exposed to information that would not be known or available at prediction time. The most common reasons are:
- Incorrect feature engineering: Including features that are directly or indirectly derived from the target variable. For example, when predicting house prices, include a feature like “price per square foot” that is calculated using the target variable (house price).
- Pre-processing mistakes: When preprocessing the data, if the target variable is used to guide any transformation, aggregation, or imputation, it can introduce leakage. For example, using the target variable to fill in missing values in input features.
- Failing to properly account for time: Using future information to predict past events, which is not possible in real-life situations. For example, using customer churn data from 2023 to predict customer churn in 2022.
Now that we understand target leakage at a high level, let’s talk about why we need to be on the lookout for it when leveraging GPT for feature augmentation.
The easiest way to explain this is by way of an example. Imagine we are trying to build a model to predict how likely startups are to either get acquired or go public. We have a handful of features about each startup such as the company name, total venture funding, trailing twelve-month revenue, number of employees, industry, etc.
To get even more features, and because we fancy ourselves a bit clever, we pass the company names to the GPT API and ask it to give us a detailed description of the company (e.g. reputation, product, founders, etc.)
As instructed, GPT dutifully responds with a detailed description of each of our companies that we can pass along to our model. Let’s take a look at an example response:

Example response
At this point, you may be thinking, what’s the problem? This seems awfully kitteny and rainbowish to me — we now get to mine all this free text and incorporate information like the company’s headquarters and platform capabilities into our model that we didn’t have access to beforehand.
While you’re right that this new information seems beneficial, unfortunately, we don’t have any timestamps around when the data was pulled. If the DataRobot entry in our dataset was as of 2018 and chatGPT’s description incorporated information as of 2023, we would be leaking information from the future into our training data. This type of target leakage is closely related to the idea of survivorship bias that you often find in financial models. The simple fact that DataRobot is still an active entity today is information that the model couldn’t possibly know when making a prediction in 2018.
So, how can we address this? While I don’t have a scientifically robust answer for you, I would recommend the following: update your prompt to instruct GPT to only provide answers up to a certain point in time.
Here’s a simple example of what I mean:

We can see two things here: first, chatGPT was kind enough to apologize to us (apology accepted), and, second, the response changed and included information knowable up through the end of December 2018 and not beyond.
Hallucination
Generative models are alarmingly good at producing confident answers regardless of actual correctness. This is a phenomenon known as hallucination:

I work with a colleague that refers to hallucination as a “truthiness problem” where these generative models have no problem inventing information and presenting it as indisputable fact.
While it’s not hard to catch the fact that Christof Wandratsch likely didn’t cross the English Channel on foot, there are many other scenarios where hallucinations pop up that are far more difficult to catch.
Topic Drift
The longer you interact with today’s generative models, the more likely they are to veer of course and begin discussing topics completely unrelated to the original prompt.
In machine learning, the idea of data shifting over time is known as data drift. Topic drift works just like data drift except that we’re measuring how similar or relevant each response is to the original topic rather than measuring how similar a particular feature’s distribution is across two different periods of time.
To measure topic drift, we can plot a word cloud, only with a bit of a twist. In this version, the size of the words corresponds to the token’s overall impact on our drift score and the color corresponds to how much more or less often the token appeared over time.

The term “ai” in the center is large and red, indicating that we’ve seen more mentions of ai recently and ai is significantly contributing to the overall drift across our text field.
Are there any other ways to mitigate topic drift? Sure! We can turn to AI to help us solve our AI problems (fight fire with fire as they say). The simplest way to ensure that generative models are staying on topic over time is to build (or leverage an existing) model that predicts topics from a blob of text. This model can then serve as a babysitter to our generative model and output or a warning (or even a timeout) whenever the topic of the response is too dissimilar to the topic of the original prompt.