
Search is a conversation: a dialogue between user and system that can be every bit as rich as human conversation. And like human dialogue, search works best when the exchange is based on a shared understanding that helps people express themselves more effectively.
In my previous article we looked at techniques to help users create and articulate more effective queries, using techniques such as auto-complete and auto-suggest. From simple fact finding to complex exploratory search, these techniques can often make the difference between success and failure.
But things can still go wrong. Sometimes a searcher’s information journey is more complex than they’d anticipated, and they find themselves straying from the ideal course. Worse still, in their determination to pursue the original goal, they may overlook other, more productive directions, leaving them endlessly finessing a flawed strategy. Sometimes they are in too deep to turn around and start again.
Conversely, there are times when searchers may consciously decide to take a detour and explore the path less trodden. What they find along the way can change what they seek. Sometimes they find the most valuable discoveries in the most unlikely places.
However, there’s a fine line between these two outcomes: one person’s journey of serendipitous discovery can be another’s descent into confusion and disorientation. And there’s the challenge: how can we support the former, while unobtrusively repairing the latter? In this post, we’ll look at four techniques that help users stay on the right track on their information journey.
Did You Mean
In my earlier article on as-you-type suggestions, I discussed how auto-complete and auto-suggest are two of the most effective ways to prevent spelling mistakes and typographic errors (i.e. instances where users know how to spell something, but enter it incorrectly). By completing partial queries and suggesting meaningful alternatives, we avoid the problem at source. But, inevitably, some mistakes will slip through.
Fortunately, there are a variety of coping strategies. One of the simplest is to use spell-checking algorithms to compare queries against common spellings of each word. The figure below shows the results on Google for the query “expolsion”. This isn’t necessarily a ‘failed’ search as such (as it does return results), but the more common spelling “explosion” would return more a productive result set. Of course, without knowing our intent, Google can never know for sure whether this spelling was intentional, so it offers the alternative as a “Did you mean” suggestion at the top of the search results page. Interestingly, Google repeats the suggestion at the bottom of the page, but with a slightly longer wording: “Did you mean to search for”. This is a subtle clarification, but one that may reflect the user’s shift in attention at this point (from query to results).
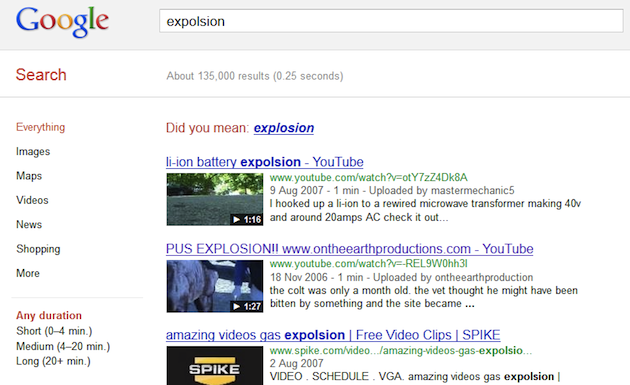
Potential spelling mistakes are addressed by a “Did you mean” suggestion at Google
Likewise, most major online retailers apply a similar strategy for dealing with potential spelling mistakes and typographic errors. Amazon and eBay both conservatively apply Did You Mean to queries such as “guitr,” faithfully passing on the results for this query but offering the alternative as a highlighted suggestion immediately above the search results. And in Amazon’s case, the results for the corrected spelling are appended immediately below those of the original query:
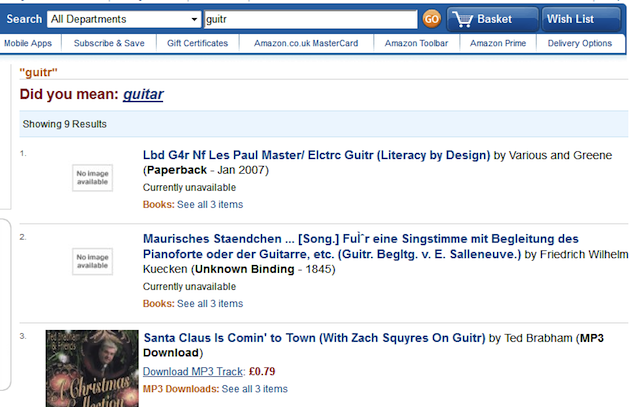
Did You Mean at Amazon
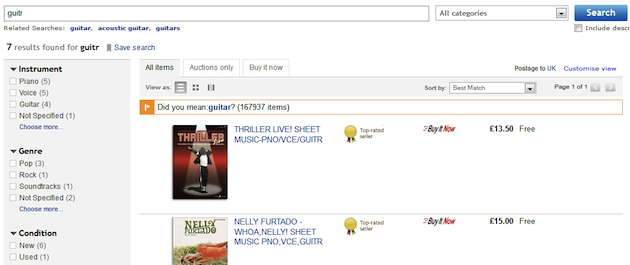
Did You Mean at eBay
Auto-Correct
Search engines may be capable of many things, but one thing they cannot do is read minds: they can never know the user’s intent. For that reason, when faced with queries like those above, it is wise to keep some distance. Offer a gentle nudge, but leave the choice with the user.
However, there are times when it seems much more apparent that a spelling mistake has occurred. In these cases, we may not know for sure what the user’s intent was, but we can be fairly certain what it wasn’t. In these instances, auto-correction may be the most appropriate response. For example, consider a query for “expolson” on Google: this time, instead of applying a Did You Mean, it is auto-corrected to “explosion.” As before, a message appears above the results (“Showing results for”), but this time, the choice has been made for us:
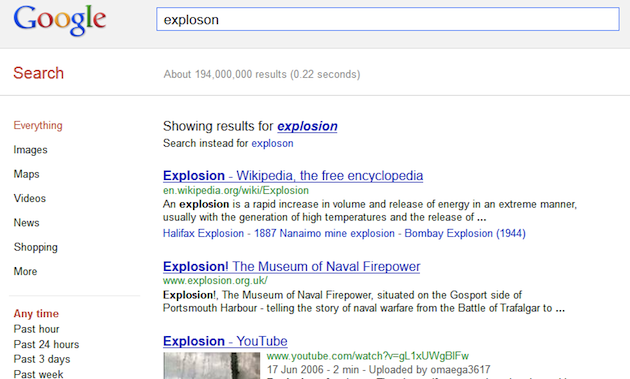
Auto-correct at Google
It seems that this time Google is more confident that our query was unintended. Without knowing our intent, how can it determine this? (In case you’re wondering, it’s not simply by looking for relatively low numbers of results: “expolsion” returns about 135,000 results, and “exploson” returns approximately 222,000, yet the latter auto-corrected while the former is not.) The answer lies in what Google researchers refer to as the “Unreasonable Effectiveness of Data”—in this instance, the collective behaviour of millions of users. By mining user data for patterns of query reformulation, Google can determine that “exploson” is more likely to be corrected by users than “expolsion”. Knowing this, it applies the correction for us.
In fact, Google applies the same insight to its auto-suggest function —in addition to completions based on the prefix, it also returns potential spellings. This is particularly important in a mobile context, when accurate typing on small, handheld keyboards is so much more difficult.
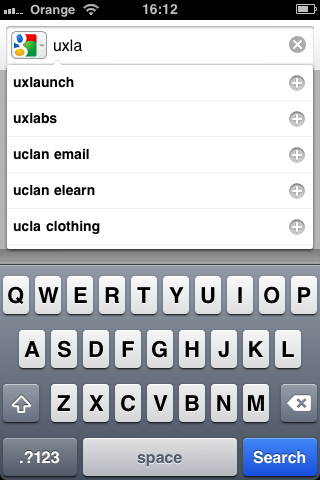
Query suggestions include spelling corrections on Google
These strategies make a significant difference to the experience of searching the web. However, for site search, such vast quantities of user data may not be so readily available. In this case, perhaps a simple numeric test could suffice: for zero results, apply an auto-correction; for greater than zero but less than some threshold (say 20 results), offer a Did You Mean.
Partial Matches
The techniques of auto-correct and Did You Mean are ideal for detecting and repairing simple errors such as spelling mistakes in short queries. But the reality of keyword search is that many users over-constrain their search by entering too many keywords, rather than too few. This is particularly apparent when confronted with a zero results page: for many users, the natural reaction is to add further keywords to their query, thus compounding the problem.
In these cases, it no longer makes sense to replace the entire query in the manner of an auto-correct or Did You Mean, particularly if certain sections of it might have actually returned productive results on their own. Instead, we need a more sophisticated strategy that considers the individual keywords and can determine which particular permutations are likely to produce useful results.
Amazon provides a particularly effective implementation of this strategy. For example, a keyword search for “fender strat maple 1976 USA” finds no matching results. However, rather than returning a zero results page, Amazon returns a number of partial matches based on various keyword permutations. Moreover, by communicating the non-matching elements of the query (using strikethrough text), it gently guides us along the path to more informed query reformulation:
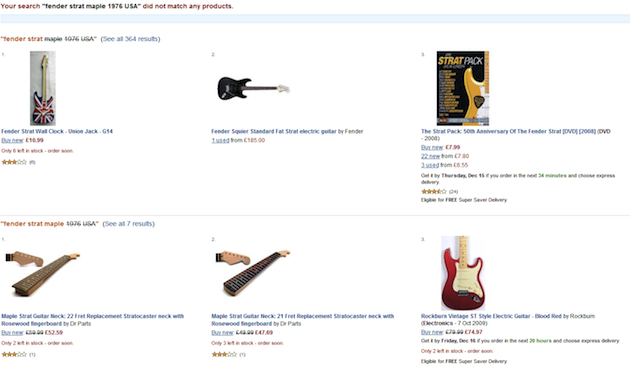
Partial matches at Amazon
Although conceptually simple, solving the partial match problem is non-trivial: a long query has dozens of permutations, of which only a fraction will return useful results. In addition, out of all those variations, there is only space to present results for a handful, so they need to be chosen to reflect the diversity of the matching products while avoiding duplicate results.
A similar strategy can be seen at eBay, which also finds no results for the same query shown above tried on Amazon. Instead of a zero results page, we see a list of the partial matches with an invitation to select one of them (or to “try the search again with fewer keywords”). These are ordered using what’s known as quorum-level ranking (Salton, 1989), which sorts results according to the number of matching keywords. In other words, products matching four keywords (such as “fender strat maple USA”) are ranked above those containing three or fewer (such as “fender strat USA”).
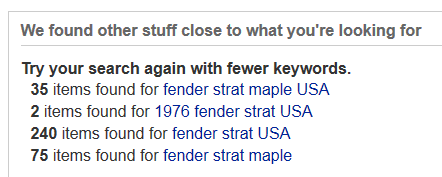
Partial matches using quorum-level ranking at eBay
Partial matches are a very effective way to facilitate the process of query reformulation, providing users with a clear direction to take along their information journey. Together with auto-correct and Did You Mean, they act as signposts that help users decide which path to take. But sometimes users may see something that motivates them to take a deliberate detour. Like the auto-suggest function we discussed earlier, related searches provides us with the inspiration to embrace new ideas that we might not otherwise have considered.
Related Searches
All the major web search engines offer support for related searches. Bing, for example, shows them in a panel to the left of the main results:
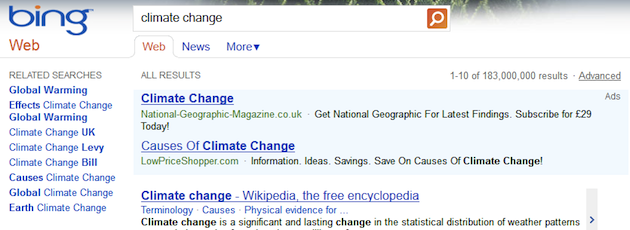
Related searches at Bing
Google, by contrast, shows them on demand (via a link in the sidebar) as a panel above the main search results. Both designs differentiate between extensions to the query and reformulations—any keywords that are not part of the original query are rendered in bold.
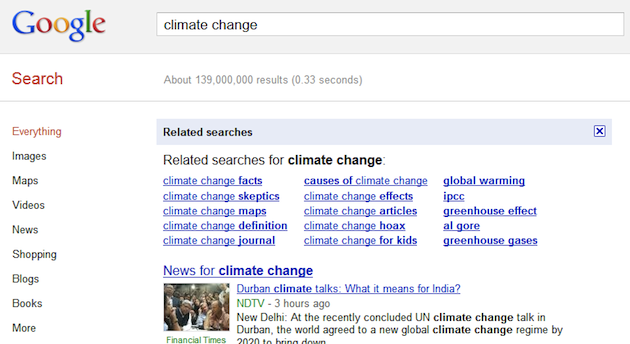
Related searches at Google
Apart from providing inspiration, related searches can be used to help clarify an ambiguous query. For example, query on Bing for “apple” returns results associated mainly with the computer manufacturer, but the related searches clearly indicate a number of other interpretations:

Query disambiguation via related searches at Bing
Related searches can also be used to articulate associated concepts in a taxonomy. At eBay, for example, a query for “acoustic guitar” returns a number of related searches at varying levels of specificity. These include subordinate (child) concepts, such as “yamaha acoustic guitar” and “fender acoustic guitar”, along with sibling concepts such as “electric guitar”, and superordinate (parent) concepts such as “guitar.” These taxonomic signposts offer a subtle form of guidance, helping users better understand the conceptual space in which their query belongs.

Taxonomic signposting via related searches at eBay
While related searches offer a way to open minds to new directions, they are not the only source of inspiration. Sometimes the results themselves provide the stimulus. When users find a particularly good match for their information need, they try to find more of the same: a process that Peter Morville refers to as “pearl growing” (Morville, 2010). Sometimes the action to find more of the same is one we can directly initiate: Google’s image search, for example, offers users the opportunity to find images similar to a particular result:
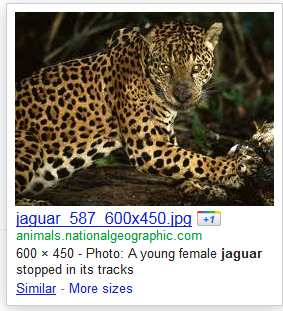
Find similar images at Google
For image search, the results certainly appear impressive, with a single click returning a remarkably homogenous set of results. But that is perhaps also its biggest shortcoming: by hiding the details of the similarity calculation, the user has no control over what it returns, and cannot see why certain items are deemed similar when others are not. For this type of information need, a faceted approach may be preferable, in which the user has control over exactly which dimensions are considered as part of the similarity calculation.
While Google shows how we can actively seek similar results, sometimes we may prefer to have related content pushed to us. Recommender systems like those employed by Last.fm and Netflix rely heavily on attributes, ratings, and collaborative filtering data to suggest content we’re likely to enjoy. And from just a single item in our music collection, iTunes Genius can recommend many more for us to listen to as part of a playlist:
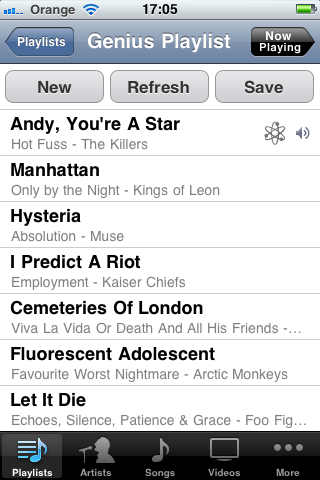
Genius playlist creates “more like this” from a single item
Summary
Query reformulation is a key component of information seeking behavior, and one where we benefit most from automated support. Did You Mean and auto-correct apply spell checking strategies to keep us on track. Partial matching strategies provide signposts toward more productive keyword combinations. Last but not least, related searches can inspire us to consider new directions and grow our own pearls. Together, these four techniques keep us on track throughout our information journey.
Track bicycles photo courtesy of J.A.Astor / Shutterstock.com


