We live in the age of AI! Every day, many new AI tools and ML models are being created, trained, released, and often advertised. When looking at
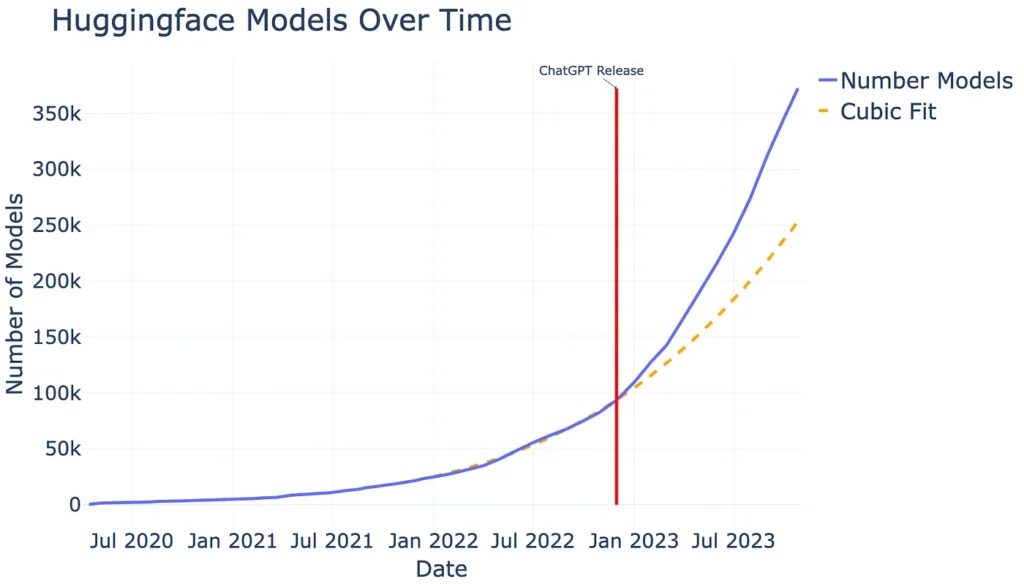
Hugging Face for instance, we see almost 400,000 models available today (2023–11–06) compared to the ~84,000 models available in November 2022 (see Figure 1). In just one year, there’s been a massive increase of roughly 470% in the number of models. Remember, Hugging Face isn’t the only ML model platform out there. Plus, many models aren’t even open-sourced. So, it’s safe to say the actual number of available ML models is much higher.
is there truly a need for such an overwhelming inflation of models?
The excitement about AI is huge and that is first and foremost good. AI has the potential to find solutions for — or at least mitigate — some of the most severe global challenges like climate change or pandemics. In addition, AI can make everyday tasks more efficient and, thus, improve our work-life balance. Hence, research and development of AI and making ML models available to the community is the right and necessary step! However, with the given development speed and excitement in the AI community I am wondering: is there truly a need for such an overwhelming inflation of models? Who, ultimately, will benefit from this?
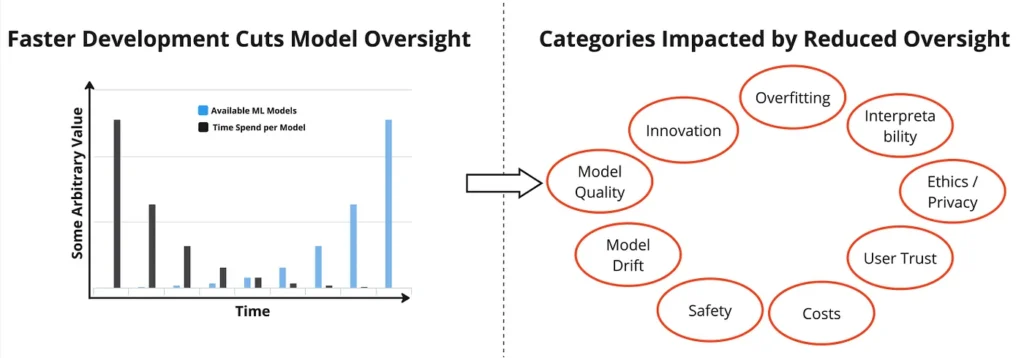
Potential Risks of Model Inflation
One of the common drawbacks of “excitement” and “hype” for a given topic is when the derived motivation and work are not specifically directed to a goal but are more superficial and broad. The aforementioned potential benefits of AI do not come from having a lot of superficial models, they come from specialized models which tackle hard problems.
In addition to that, the current speed in model development, deployment, and advertisement comes with some disadvantages we all have probably encountered already. It is important to address these issues to ensure the best outcomes in the future. Some potential drawbacks of the current speed in AI development:
- Quality: with the speed to market, it is already too hard to follow up with the community and properly review model outcomes and research papers. The downside will be a large number of available models and services with low quality since they have not been rigorously tested and reviewed. Also supporting quality metrics like confidence intervals are mostly dropped due to speed to market.
- Impact + Safety: a large amount of models being developed these days are not human (or nature) centric and do not have a very useful target or use case in mind. However, every product development should always focus on making the world a better place. Developers must focus on what can have a positive impact and not develop “just another chatbot”. In addition to that, developers also have to rule out potential harm coming from their model and ensure safety (similar to this proposal).
- Privacy + Copyright: Models are rarely documented and it is hard to follow how privacy and copyright have been addressed. This can have negative consequences for individuals. When working with sensitive data, modeling is dangerous since even a vector database after embedding is not privacy-friendly and can easily be reverse-engineered (as shown by Morris et al. 2023). Also, new regulations like the EU AI Act will have an impact on those models, enforcing privacy compliance.
- Investment Loss: Even with a fast speed to market, any AI project requires resources (highly skilled engineers, substantial computing costs, product maintenance). The return on investment for a business is not given if the resulting AI product is of low quality or doesn’t serve a clear user purpose. It is common practice to have a product discovery phase before developing a product to anticipate the potential return on investment. This practice is often violated for AI with the current speed to market.
In summary, the fast speed in AI development is not only a good thing, but it also causes potential friction and downsides for businesses and individuals.
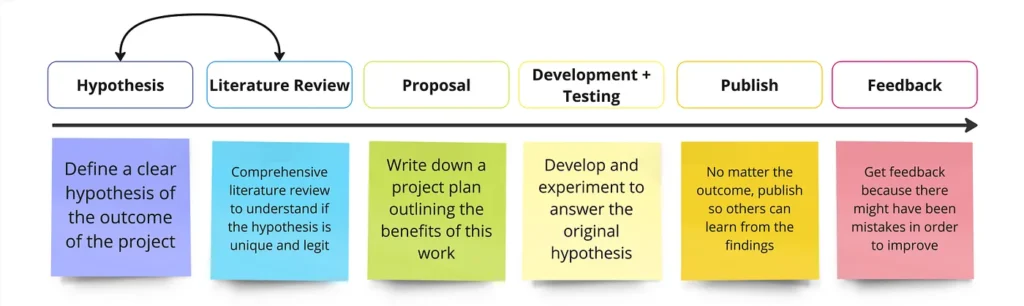
Reduce Model Inflation by Hypothesis-Driven Development
As mentioned earlier, the current excitement around AI is foremost a good thing. The purpose of this story is not to stop AI development or to slow it down. Quite the opposite. The intention is to direct the positive excitement on specific objectives and create quality rather than quantity. The idea is to encourage every AI Engineer and Data Scientist to just take a little bit more time at the very beginning of each project and ask some fundamental questions, like: “Who would benefit from this?” and “What do we want to achieve?”.
what this story is proposing is not revolutionary at all, it is simply to follow scientific methods.
Instead of an exploratory approach where one starts to just develop the next LLM without a clear vision and, thus, inflating the community, how about starting at the very end and discussing the product use case? That could be for instance to come up with an objective for the project first, for instance: “Current foundational LLMs are very complex and can hardly run on-premises. That we would like to tackle”. With this, the project becomes meaningful. But meaning is not everything, a clear hypothesis will make the work even more streamlined. For instance:
“It is possible to train a lightweight LLM that can be run on-premises and still performs >70 on the LLMU benchmark set”.
Having a clear objective and derived hypothesis in mind will help to streamline the entire development work. It will also help measure success and make a meaningful contribution to the community. Combined with a literature/model review, it will immediately outline if the proposed project has been already achieved elsewhere and, thus, is only creating redundant work. In other words, what this story is proposing is not revolutionary at all, it is simply to follow scientific methods.
The Spark of Innovation
The reason for proposing scientific methods is that the current issues derived from a fast development speed in AI are well-known to the scientific community. Scientists have to learn from an overwhelming amount of research papers to make a meaningful contribution to the research community. Together with the speed of large research labs, it is easy to develop a feeling of “not having enough time to read everything”. This and the publication pressure have already led to the reproducibility crisis. Scientific methods are here to overcome those issues.
Scientific methods have been developed and improved over centuries and are standing at the core of any scientific project. Given that the fast pace of AI development is very similar to the overwhelming amount of scientific literature, it makes sense to adapt those principles.
A lot of scientific breakthroughs did not start in the lab, they started with a thought which was shaped into a hypothesis
As a positive side effect, the scientific methods were not only developed to standardize work and experimental outcomes but they were also made to enhance innovation. Taking time to review existing literature and formulating hypotheses is at the core of innovation. A lot of scientific breakthroughs did not start in the lab, they started with a thought which was shaped into a hypothesis.
The scientific community, for instance, offers the option of preregistration. That means, scientists publish their objectives, hypotheses, and methodology first before actually conducting the experiments and analysis. This concept could also be applied to AI development.
That being said, I highly encourage everyone to outline an objective with hypotheses before starting any AI or ML project! In addition, I hope that
Hugging Face and other prominent platforms someday require Engineers and Scientists to preregister their objectives and hypotheses first before they can start working on a model. I am sure if a large platform like Hugging Face starts, others will follow.
Summary
The current speed in AI development is both exciting and challenging at the same time. Exciting about the benefits those new models bring but challenging due to the overwhelming amount of available models and the unknown about their underlying quality, privacy, safety, and return on investment.
Scientific methods, like hypothesis-driven development, can help overcome those issues and can even foster innovation by ensuring AI / ML Engineers and Data Scientists are focused on developing towards a pre-defined objective and hypothesis.
It is the age of AI so it is most important to make sure we make the best future out of it for all of us.
All images, unless otherwise noted, are by the author.
This article was originally published on Towards Data Science.