

Information wants to flow and it wants to flow freely and torrentially. Twitter, SMS, email, and RSS offer unprecedented access to information. With all these channels of communication comes a deluge of overwhelming retweets, cross-chatter, spam, and inaccuracies. How do you distinguish signal from noise without getting overwhelmed? Can we somewhat automate the process of filtering content into more manageable portions without sacrificing accuracy and relevance?
These are the exact questions I attempted to answer during the recent earthquakes in Haiti and Chile. As the Director and System Architect of SwiftRiver at Ushahidi, we’re working on an open-source software platform that helps journalists and emergency response organizations sift through real-time information quickly, without sacrificing accuracy. These earthquakes, however unfortunate, offered extreme use-cases for testing ideas internally, as small nonprofits and organizations as large as the U.S. State Department were relying on us for verified information.
The approach SwiftRiver takes is to combine crowdsourced interaction with algorithms that weight, parse, and sort incoming content. But before we get to that, let’s explore how real-time content is currently delivered and consumed.
User Experience and Real-Time Content
As we move into the future of the Web, it’s clear that real-time content is going to remain an increasingly important part of our online experience. This makes it important to think about the implications these new ways of delivering information have for UI design. We’ve learned from design for Web 2.0 that less is more. The buzzword simplexity was tossed around for a while to describe applications that did a lot under the hood, while managing to look simple on the frontend.
The layout of google.com is often cited as a good example of simplexity. When you navigate to Google you’re presented, front and center, with a box that essentially asks you one question: what are you looking for? You type a phrase, and the application returns the results. That seems like a very simple exchange, but software professionals can tell you there’s an incredible amount of work that goes into making such a simple task appear so…ordinary.
Likewise, other websites like mint.com and flickr.com, while not real-time apps, are great examples of making complex sets of processes seem easy. Many other websites have taken completely different approaches to both tasks (Web-based finance tracking and photo sharing, respectively), but I’d propose that these two sites have succeeded because of ease of use and accesibiity as much as because of the services they offer. Arguably, they’re more successful in comparison to their former competitors as a result. So the simplicity of user interactions is important; and can have a direct return in increased user engagement.
With real-time apps, the need for simplexity is compounded by the fact that simple needs to be fast, and easy to read. In short, they need to answer the user question, “What am I supposed to pay attention to and when?”
At this year’s CHIRP Conference, Twitter revealed that it’s attempting to address some of these very issues. They previously only offered a few tools for the curation of user streams. Search is one such mechanism; to find something that’s already been said, we can search the backlog of tweets at search.twitter.com. The lists feature is another; to set up filters that continually organize what’s being said by people we trust on a given subject, we create lists of people knowledgeable on that subject. It’s a list curated by repuation, but it still needs to be created. And, finally, the act of following or unfollowing users is another mechanism of curation. Who’s saying the things that we care about enough to listen to at all?
Even still, the information available through Twitter is ephemeral. If we go away from our Twitter accounts for a week, a day, an hour—hell, sometimes even a few seconds—we’ll receive content that’s very different than the content delivered at any other period of time. This is a relatively new problem, a by-product of technology as we to speed up the means for communication.
But are these mechanisms for curation more useful or are they just more tools? More access to conversations from people whom we may or may not care about in all scenarios is both a gift and a curse. When I do care, the information is there. When I don’t, I still have to try to sift through it all to find what I’m looking for. The developers at Twitter recognize this and are now experimenting with algorithmic and manual approaches to drawing user attention to information that they deem relevant with sponsored tweets, popular tweets, and resonance.
The Existing Workflow
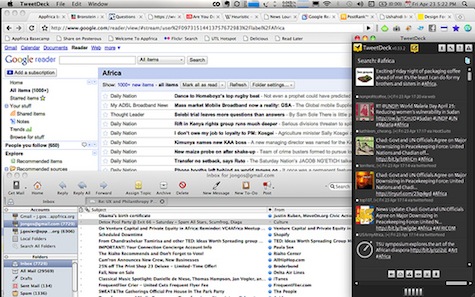
Right now emergency response organizations and journalists monitoring real-time news have workflows that involve several independent tools: a Twitter desktop client (like Seesmic, Twhirl, TweetDeck, Tweetie, etc.), email, phone, feed readers, Google Alerts, and so on. The tools are there but they’re scattered, offering little (if any) cohesion.
Curating Reputation
If there’s a unsolved problem here, I propose it’s this: there’s no easy way to aggregate the trust that a user has for specific content sources—In other words, a way to carry the reputation I may have for various individuals across the Web with me.
You can make the decision that Blogger X is more reliable than Blogger Y, but just because Blogger X is authoratative most of the time on most subjects doesn’t mean he will be all the time. On Wikipedia, for instance, changes to articles need to be approved by a group of peers. Some users (editors) are given the rights to approve, disapprove, and edit the changes of other users, and they only answer to an even smaller group of peers and they hold more authority within that ecosystem than others. However, you’ll also notice on Wikipedia that authoratative editors for entries on Steve Jobs aren’t the same editors for Rush Limbaugh’s profile.
Editors at Wikipedia have to demonstrate they are both knowledgable on a subject and reliable enough that they won’t sacrifice accepted truth for personal bias. That’s one example. Ranking by influnce or popularity is another. An example of this is Twitter’s new feature, Resonance. By measuring retweets, click–throughs, and other interactions, it determines the influence of a tweet.
So that’s reputation at its most basic level. Distributed reputation, then, is the aggregate reputation accrued by a person’s contributions across the Web. This is hugely important for changing the way we consume content because it helps users focus their attention on other users that have proven to offer the most value. When I’m reading the New York Times online and I look to the comment section of an article, might there one day be a way to see who among the commnetors has previously demonstrated they know what they’re talking about within the article’s specific context? If so, we could then filter the conversation by reputation rather than popularity.
With a distributed reputation system, the decisions of whether a source is trustworthy can be passed back to applications in ways that adds context to future decisions. Reputation can be applied to users as well as content sources. It can then be used as the basis for a number of filters: authority by subject, authority within an organization, on a social network, or in my feed reader. It becomes a baseline we can use in a lot of ways.
The location of the source of content should also influence reputation. Where an event occurs tells a user as much about why he should care about as when it occurred. Was the person actually in Iran when he tweeted that media in Tehran was shutdown? If so, then we’ll probably be more interested in the following messages from that user than the guy in Australia recounting the events as they unfold from BBC World News coverage or even the BBC itself.
Why? If trust can be earned, then it can also be lost, so it needs to be continually maintained. After all, because a source was right once, twice, or even a thousand times, doesn’t make it always right—and certainly not on every subject. Even big news organizations are limited in what they cover and how well or quickly they can cover it.
This past year in Kampala, Uganda, there were a series of deadly riots that occured under the radar of international mainstream news for days. Yet it was a situation that affected millions of lives here. My peers and I relied upon Twitter and SMS for information. Later, when the mainstream news picked up on what was going on, they were often wrong or misleading in what they reported.
In such a scenario, the news outlets were either clueless, or useless to people like myself. Conversely, friends of mine who were chased down by military police as they tweeted absolutely earned my trust. In that situation, I followed the information sources that it made sense to monitor for that situation. Every scenario will be different, which is why a good distributed reputation system should be equally nuanced.
Speed of Delivery and Consumption
Another focus is the speed of delivery, as well as how quickly content can be presented or consumed. The real-time workflow is all about speed—staying as close to moments of occurrence as possible. After all, “breaking news” isn’t breaking because it’s being reported a week after everyone else reported it. It’s breaking because it’s happening right now. A volcano in Iceland was recently shooting plumes of ash and rock 35,000 feet into the air and causing historic disruptions of air travel. At one point in time that was breaking news. It might very well still be news, but the real-time coverage of that event is no longer important. It has already happened.
Time is the enemy when dealing with real-time content. How long does it take someone to receive the report of a shooting at Fort Hood on Twitter? It could easily be seconds, providing that they have a good Internet connection and Twitter’s servers aren’t down. However, it could take far longer. If information is only important now, or most important now, there won’t ever be a better time to get that content to whomever might be looking for it. A real-time application that’s slow in delivering information is obviously self-defeating. Tools like pubsubhubbub, Ajax, and jQuery are are possible parts of the solution here, as is the optimization of databases and other background processes.
Managing Real-Time Information Channels
The newest version of NetVibes offers a unified dashboard that allows users to manage their email, text messages, RSS feeds and other content from around the Web in place. But how can we allow this to happen autonomously without a central server or organization acting as the gatekeeper? With our platform, SwiftRiver, we are attempting to answer these questions.
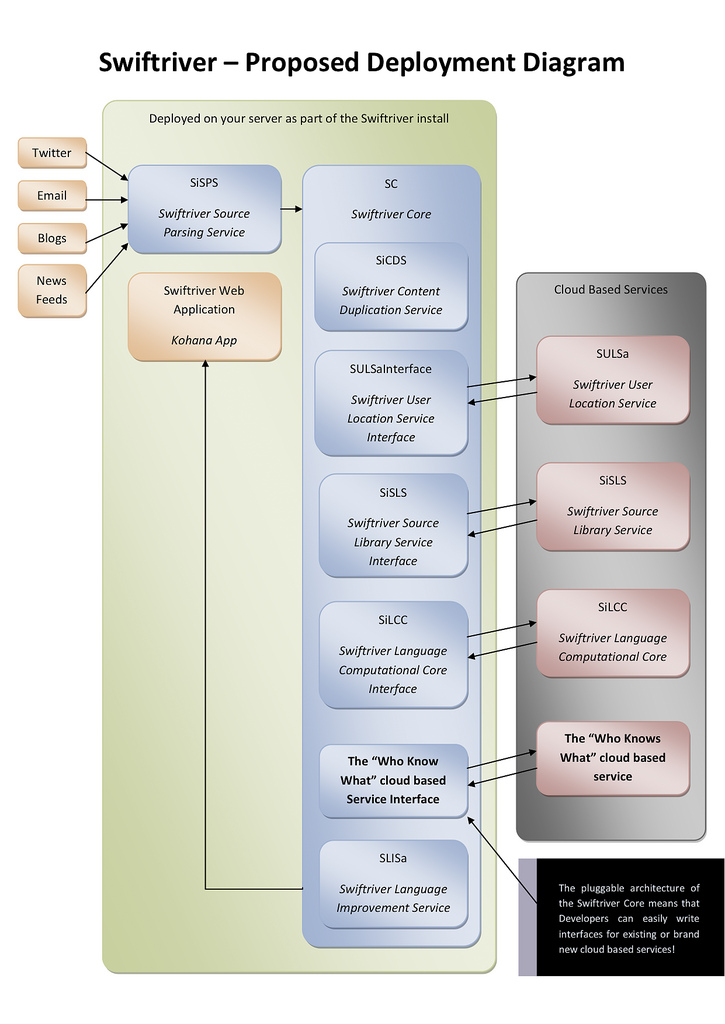 SwiftRiver is an open source project being developed for aggregating and managing multiple channels of real-time news from the Web, including crowdsourced content from Twitter, SMS, and email. It attempts to streamline the mining fo data in real-time in a number of ways.
SwiftRiver is an open source project being developed for aggregating and managing multiple channels of real-time news from the Web, including crowdsourced content from Twitter, SMS, and email. It attempts to streamline the mining fo data in real-time in a number of ways.
Structuring Unstructured Data
The only reason we as content consumers tend to treat data differently is because of the different tools we normally use to receive them. In a scenario like the Haiti earthquakes, we needed to find information that was urgent across many differnt types of media quickly. We quickly realized that it was exceedingly inefficient to monitor hundreds of different information sources from different applications (Twitter, RSS, SMS, and email) so we developed SwiftRiver to centralize similar flows of information.
The flow of data within our application begins with aggregating unstructured (rather, differently structured) datasets, reformatting them through various processes, centralizing them in our database, and then returning one unified feed. Once the data is aggregated, SwiftRiver does three things to optimize it. We filter out duplicate content, structure data into a unified object model, and then use our natural language processing program, SiLCC, to extract keywords and apply them as tags.
When users launch their SwiftRiver instances, they’re already dealing with structured data. This allows them to worry about more important things like what the information is telling them and (in the case of emergency response organizations) how they might need to respond.
Persistent Tagging
The automation of the tagging process saves a great deal of time. Many social news sites rely solely upon their users to tag content to varying degrees of success. This approach places this feature at the mercy of user engagement. If user engagement is high, tags are created as desired. If user engagement is less than average, then some content won’t get tagged at all. I’m of the opinion that tags are grossly unappreciated as they add the first layer of semantic taxonomy to content on the Web.
We’ve attempted to solve the problem of lackluster tagging by users with auto-tagging algorithms performed by our SiLCC app, which ensures that all aggregated content (tweets, emails, text messages) are tagged and sorted. This means that there is at least some level of taxonomy available to all aggregated content, regardless of the source. Since user engagement is a variable that we cannot predetermine, we instead use active learning techniques to apply those interactions (where they exist) to the improvement of the algorithm.
Text is parsed, entities are extracted, semantic meaning is deduced, and the program learns from its mistakes through user feedback. SiLCC was specifically built to address the auto-tagging of tweets and text messages, tasks that groups like Open Calais, TagThe.Net, and other semantic Web applications don’t currently offer.
Veracity
We represent trust of sources with what we refer to as the veracity score. This score is the acculmulated authority of a content item’s source. For an email, the source would be the sender’s email address; for a Tweet, it would be the user’s Twitter account name; for blogs and news, it’s the website or feed URL; and for an SMS, it’s the sender’s phone number. As users rate individual items, the source accumulates a score that weights other content from that same source. The allows content producers whom users repeatedly deem authoritative to rise to the top. This speeds up the process of filtering through larger datasets—say, hundreds of feeds—that one might be monitoring.
The user can then deal with trusted content prior to dealing with unknown or less reliable sources. A veracity filter control sets a bracket range (high and low) for the type of content sources aggregated. In crisis situations, it’s critical that the user be able to sweep through all the sources deemed to be authoritative (those with high scores) first, before dealing with anything else. This doesn’t imply that the rest of the aggregated content doesn’t need to be dealt with; it simply prioritizes information from sources that have been reliable in the past. The score itself is also dynamic—because trust is earned, it can also be lost.
This goes back to the idea of an aggregate distributed reptuation. In the case of the earthquakes in Haiti, the people emailing or texting with information about missing friends or people trapped under rubble would be prioritized over the thousands of people talking about sending money to the victims. Both types of conversation will turn up in a search for the hashtag #Haiti but we call the latter cross-chatter—information that’s related to the event, but not to the current conversation about that event. Thus, a SwiftRiver instance set up to track earthquakes would calculate different veracity scores than one set up to monitor donations to Haiti. The context is different so the scores are different.
Learning on the Fly
In developing SwiftRiver, we’ve learned a great deal about mining real-time content. The things we’re doing with reputation (our system is called RiverID) were conceived from a scenario exactly like the one described above about inaccurate media sources. We extended the ideas to user interaction because the system is even more powerful when the reputation of a user affects his or her authority to rate sources or other users. Persistent Tagging came about to help users sort aggregated information on the fly. The scoring of content helps users prioritize where they focus their attention. Each feature was rooted in a desired user interaction.
Before I conclude, I’d also like to add that there’s an inherent bias in Western nations (where bandwidth and Internet access is plentiful) to assume that the real-time (or near real-time) conversation begins and ends on the Web. This is simply not the case worldwide. The majority of the connected planet still relies on text messages (SMS), phone calls, and radio for news. So, perhaps as a discussion for another day, I’d like to explore the importance of developing systems with multiple points of access. We developed SwiftRiver with this in mind so people in the most remote village without smartphones, without access to the Internet, and without computers can at the very least still act as nodes of information for our Swift.
While SwiftRiver is being developed with a particular use-case in mind (monitoring emergencies) it obviously has a number of other possible applications. A system like this could be used to monitor anything: celebrity scandal, environmental news, political news. The software and ideas behind it are subject-agnostic. The contstant is how we process information to help surface the items that may be more relevant in a given scenario to our users.







