

Large language models are great at answering questions, but only if the answers exist somewhere in the AI’s knowledge base. Ask ChatGPT a question about yourself, for instance, and unless you have a unique name and an extensive online presence you’ll likely get an error-filled response.
This limitation is a problem for UX designers who want to use large language models (LLMs) as a conversational bridge between people (say, the employees of a company) and documents that don’t exist in the LLM’s knowledge base. One solution is to train LLMs on the documents you want them to know; but this approach means that you need to retrain the AI every time you add new information to the database, which takes time and costs money. There’s also evidence that, after a certain point, simply increasing the size of LLMs may actually make them less reliable.
Retrieval Augmented Generation — or RAG — helps solve this problem. By connecting LLMs with different databases, RAG enables conversation designers to create their own custom language models to replace traditional knowledge management software with language-based AI.
How RAG works
Haven’t heard of RAG before? Here’s how it works: RAG pairs LLMs with external data sources to give language models knowledge that they haven’t been trained on. A user asks a question like, “How many vacation days do I have left?”. The system performs a database search to retrieve relevant information from the connected database. In this example, the database might be a spreadsheet that tracks annual leave for employees in a company. The retrieved information is then added to the initial prompt, so that the response generated by the LLM is augmented by the most up-to-date information.
If you’ve used web-based tools like Perplexity before, then you’ve used RAG. In this case, the database is the entire internet. The question you ask the AI powers a traditional web search, and the returned information is then added to the prompt and summarized in a tidy way by a large language model.
RAG with semantic search
Like traditional knowledge management software, the ability of RAG systems to return accurate responses depends on how the database the system is attached to is searched and organized. One common RAG approach pairs LLMs with documents that have been vectorized to capture semantic relationships between text.
If the last time you heard the word “vector” was in grade 10 algebra class, picture an arrow in three-dimensional space like in the picture below. Using a machine learning process known as embedding, text is transformed into vectors like this that capture how the text looks (its orthography) and what the text means (its semantics). Text with similar orthograph and meaning has a similar vector representation and, by consequence, is stored close together in a vectorized database.
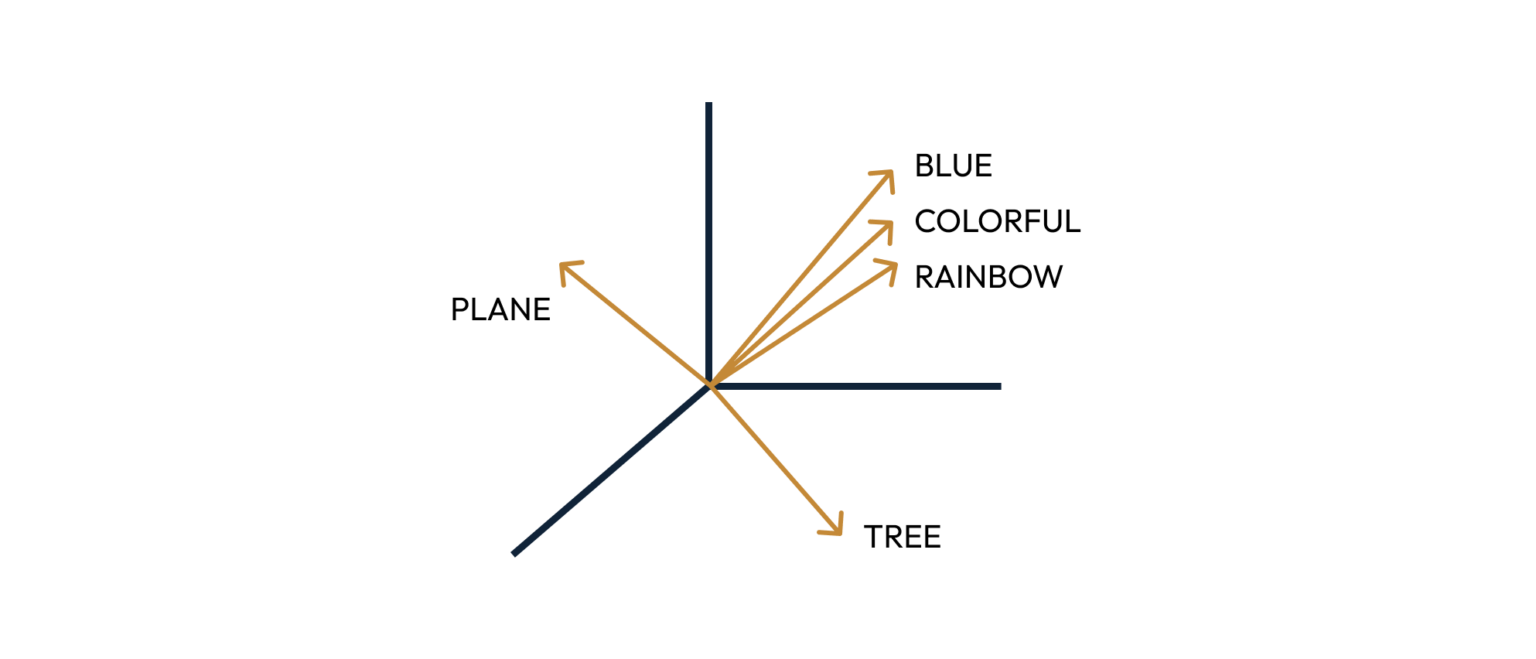
Vectorized databases enable semantic search — or a search for information based on the meaning of the search term. Semantic search can be far superior to a simple keyword search. For example, a semantic search for the word “color” returns documents with this exact term and close matches like “colorful” and “colors” — exactly what you would get with a keyword search. But it also returns documents with related vector representations like “blue” and “rainbow”. Compared to a keyword search, semantic search does a better job of returning results that capture the searcher’s intent.
Graph RAG unlocks relationships between data
Semantic search is a great addition to RAG systems, enabling users to have more meaningful interactions with text-based document collections. But if your database contains more than just text — including other forms of information like images, audio, and video — and you want to reveal hidden connections between items, powering your RAG system with an organized graph database might be a better approach.
In a graph database, information is represented by nodes connected by edges. Nodes can be things like documents, people, or products; the edges that connect the nodes represent the relationship between entries in the database.
Unlike a traditional filing system and many vector-based databases, graph databases allow users to find complex relationships between items. Take, for example, a social network of four people — Alice, Bob, Jane, and Dan. Alice and Bob are friends, Bob and Jane are friends, Jane and Alice are friends, and Dan and Alice are friends. Although the connections between these friends may seem confusing when first read, the network is easily visualized in the simple graph database below. By looking at the graph you know exactly who connects Bob and Dan (Alice, of course).
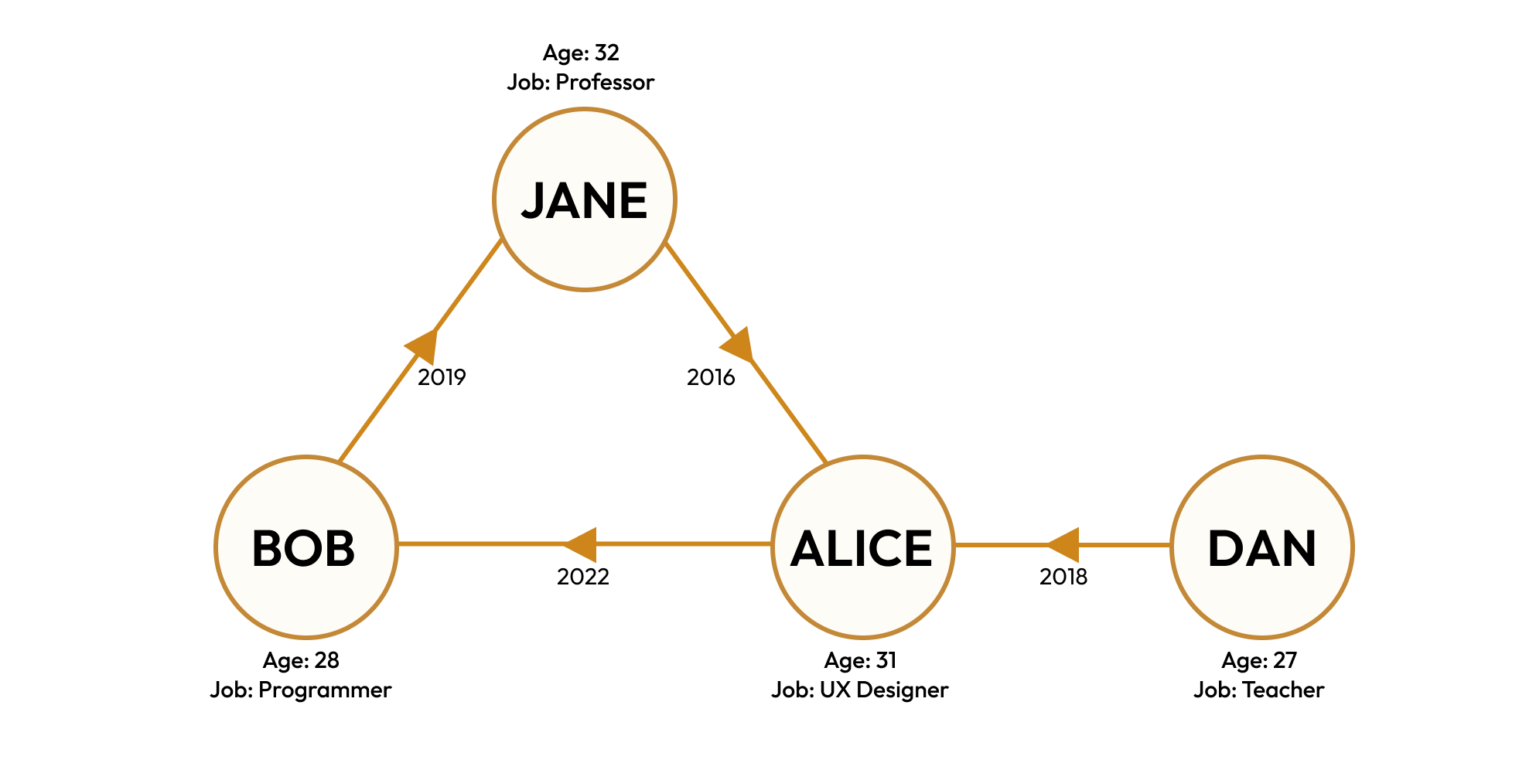
In graph databases, designers can also attach additional details to the nodes and edges. In the simple social network above, each node could store the person’s age and profession, in addition to their name. The edges connecting nodes can store the dates when friendships were established and indicate the direction in which relationships were formed. This organization allows users to track changes in the relationship between database entries as they occur in time, and also go back in time to see how relationships evolved.
When graph databases are paired with LLMs — known as Graph RAG — designers can use natural language to quickly find connections between items in databases that might have remained hidden with a more traditional filing system. Graph RAG is thus a powerful tool for using natural language to both retrieve information, and discover hidden relationships within information. This newer approach to knowledge management not only connects people to data using natural language, but it also makes data more useful.
Does RAG make sense?
Like all AI tools, RAG isn’t always the best solution. But if you want your knowledge management system to be powered by text- or voice-based commands, it might be the right tool for the job. The key to building an effective RAG system is pairing it with a well-structured, highly searchable database. If your data is primarily text-based, vectorizing the database and powering your RAG system with semantic search can lead to results that better capture the intent of the user. But if you want a knowledge management system to connect diverse sources of data — such as documents, images, and audio — Graph RAG might be the better choice. In the end, the success of any RAG system depends on pairing a good LLM with the most effective retrieval approach for your data.
The article originally appeared on OneReach.ai.
Featured image courtesy: Daryna Moskovchuk.






